For years, the language model world has operated on a simple principle: generate left-to-right, token by token, like a patient scribe writing a manuscript. This autoregressive paradigm has dominated from GPT to Llama, until now.
The dLLM framework is turning the script sideways by converting standard BERT models into diffusion-based chatbots using discrete diffusion. This isn’t just incremental improvement, it’s architectural heresy that enables bidirectional, non-autoregressive text generation, challenging fundamental assumptions about how language models should work.
When BERT Learned to Chat
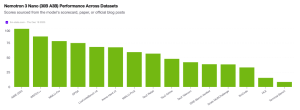
The breakthrough came from an unexpected source: ModernBERT-large, a 395-million parameter encoder-only model never designed for generation. Through masked instruction tuning with datasets like TULU-3 SFT Mixture and Smoltalk, researchers achieved something remarkable. The resulting ModernBERT-large-chat-v0 performs competitively against Qwen1.5-0.5B, despite being architecturally incompatible with traditional chat applications.
The dirty secret: Most BERT models already contain latent conversational knowledge. They just need the right training regime to unlock it.
The Diffusion Difference: Parallel Tokens and Bidirectional Thinking
Traditional autoregressive models suffer from what developers call the “sequential bottleneck”, each token must wait its turn. Discrete diffusion shatters this constraint by generating tokens in arbitrary order, sometimes filling in gaps left for later context:
“The demo shows that tokens aren’t generated strictly left to right, for example, the model may leave some masks and fill them in once the context becomes clear.”
This bidirectional capability isn’t theoretical. Tuning diffusion steps lets the model generate roughly two tokens at once, demonstrating genuine parallel generation potential. While current implementations don’t achieve full parallel generation, they hint at a future where language models think more holistically rather than linearly.
Why This Matters Beyond Chatbots
The architectural implications extend far beyond conversational AI. Recent research in Diffusion Language Models are Super Data Learners reveals that DLMs exhibit “roughly >3× data potential compared with AR models”, making them compelling alternatives in data-constrained environments.
Consider the implications:
- Better reasoning: Bidirectional context allows models to reconsider earlier decisions based on later context
- Higher throughput: Parallel token generation promises significant speedups
- Novel architectures: The dLLM framework supports training algorithms like Edit Flows with insertion, deletion, and substitution operations
Community response has been telling, many developers expressed surprise that an “encoder-only model could handle generation at all”, revealing how deeply entrenched the encoder-decoder paradigm has become.
The Practical Tradeoffs
The shift to diffusion comes with computational costs. As outlined in Sparse-dLLM: Accelerating Diffusion LLMs with Dynamic Cache Eviction, traditional DLMs “suffer from prohibitive quadratic computational complexity and memory overhead during inference.” While the Sparse-dLLM framework achieves “up to 10× higher throughput than vanilla dLLMs”, the computational overhead remains substantial compared to traditional autoregressive approaches.
The framework addresses this through dynamic cache eviction strategies that maintain “near-identical peak memory costs to vanilla dLLMs while optimizing computational efficiency.” This suggests we’re seeing the early optimization phase typical of disruptive technologies, initial overhead followed by rapid refinement.
The Ecosystem Expands
The dLLM ecosystem is maturing rapidly, with implementations for LLaDA, Dream, and specialized training pipelines supporting LoRA, DeepSpeed, and FSDP.
What makes this particularly compelling is the standardization happening around discrete diffusion for language. As researchers note in Training Optimal Large Diffusion Language Models, “masked diffusion models generally outperform uniform ones”, settling architectural debates that plagued early diffusion language model research.
The Road Ahead
The conversational BERT experiment demonstrates that our current architectural assumptions about language modeling may be unnecessarily restrictive. As one developer noted, “I couldn’t find a good ‘Hello World’ tutorial for training diffusion language models”, highlighting both the novelty of the approach and the educational gap it addresses.
The framework’s creator emphasizes dLLM’s role as “an all-in-one, tutorial-style resource” that brings “transparency, reproducibility, and simplicity to the entire pipeline.” This educational focus suggests the technology is ready for broader adoption beyond research labs.
The real question isn’t whether diffusion will replace autoregressive models entirely, but rather where each paradigm will excel. For tasks requiring global coherence planning and bidirectional context, diffusion approaches show distinct advantages. For streaming applications and strict latency requirements, traditional approaches may maintain their edge.
What’s clear is that the language model landscape is becoming more diverse, and that’s ultimately good for everyone working in the space. The age of architectural monoculture may be ending, replaced by specialized tools for specialized tasks. The BERT chatbot experiment proves even mature architectures can learn new tricks when we’re willing to challenge fundamental assumptions.
The dLLM framework and training recipes are available for experimentation, with detailed results and comparisons in the W&B report.